

今天凌晨,OpenAI 正式揭开其最强旗舰模型 GPT-5.5 及 GPT-5.5 Pro 的面纱。这套新模型的核心突破在于,它不再只是一个等待指令的对话工具,而更像一个能独自扛下复杂任务的自主执行者——从理清头绪、规划步骤,到调用工具、校验结果、持续推进,整个过程无需用户在一旁逐步插手。
先看一组硬指标:在衡量复杂终端操作的 Terminal-Bench 2.0 上,GPT-5.5 直接冲到 82.7%(前代 GPT-5.4 为 75.1%);软件工程评测 SWE-Bench Pro 得分 58.6%;内部长周期任务测试 Expert-SWE 则达到 73.1%。值得留意的是,这三项测试它都用了更少的 token 就完成了任务。在跨 44 种职业的综合评测 GDPval 中,它胜出或打平的比例为 84.9%;在模拟客服工作流的 Tau2-bench Telecom 场景中拿到 98.0%(GPT-5.4 为 92.8%);在模拟真实计算机操作的 OSWorld 里也做到 78.7%。
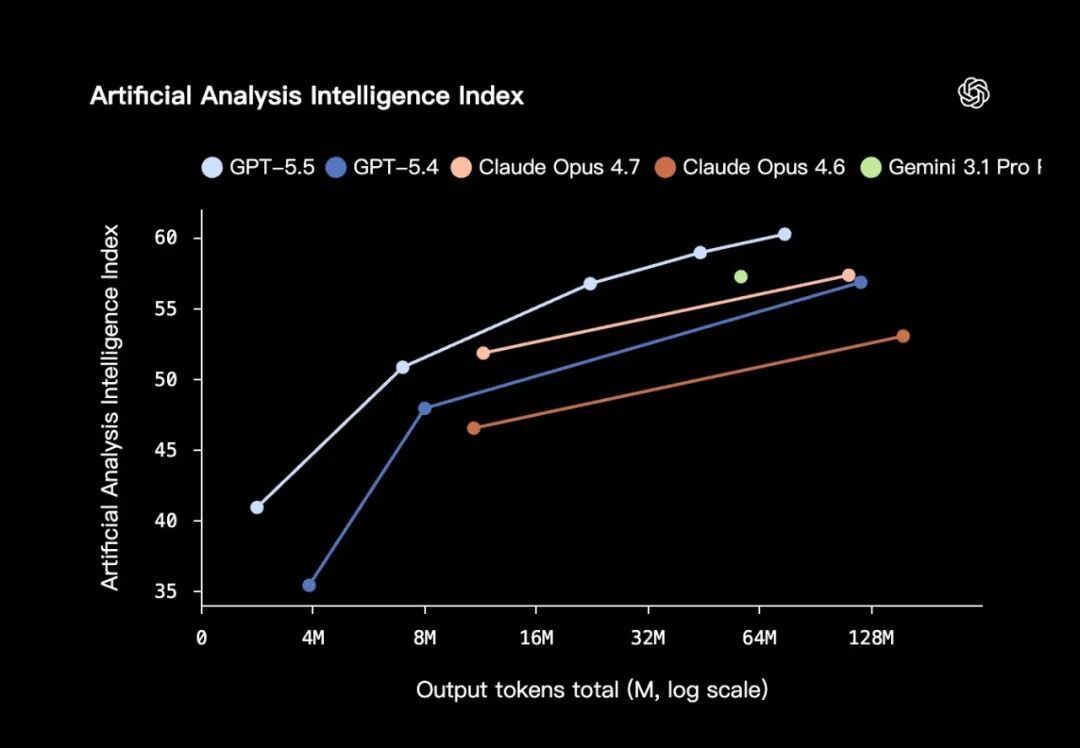
在更专精的领域,它的表现同样抢眼:生物信息学评测 BixBench 得分 80.5%,位列所有已公布成绩的模型之首。更令人印象深刻的是,一版内部模型还证明了一个关于 Ramsey 数的长期猜想,并在证明助手 Lean 中完成了形式化验证。
从底层硬件的协作来看,这套模型针对英伟达 GB200/GB300 NVL72 系统做了联合设计。结果是,它的每 token 延迟被保持在与 GPT-5.4 持平的水平上,同时通过负载均衡优化,token 生成速度反而提升了超过 20%;在执行同样的 Codex 任务时,GPT-5.5 所消耗的 token 数量也显著更少。
初批用户也给出了相当具象的评价。Cursor 联合创始人兼 CEO Michael Truell 称,GPT-5.5 面对那些漫长又复杂的任务时,能一直坚持到底,而不会像以往那样中途停摆;Every 创始人兼 CEO Dan Shipper 则亲自验证了它能够独立输出一套水准堪比资深工程师的系统重构方案。最有情感冲击力的一条评价来自一位英伟达工程师,他直言:失去 GPT-5.5 的访问权限,感觉“就像肢体被截肢了一样”。
目前,GPT-5.5 已向 ChatGPT Plus、Pro、Business 和 Enterprise 用户开放,Codex 支持最高 400K 的上下文窗口;API 版本也即将上线,标准定价方案是每百万输入 token 5 美元、每百万输出 token 30 美元,而 GPT-5.5 Pro 的 API 定价分别为 30 美元和 180 美元。
富牛证券提示:文章来自网络,不代表本站观点。



